

INTRODUCTION TO MOST COMMON KAFKA INTERVIEWS QUESTIONS
Table of Contents
What is Apache Kafka?
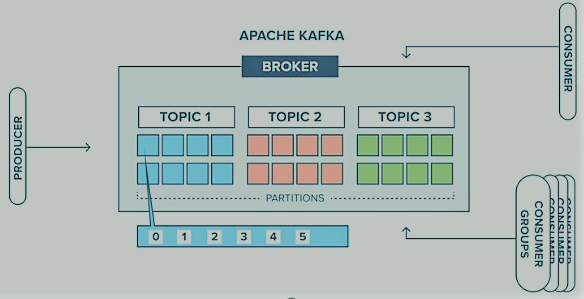
An open-source distributed event streaming platform is Apache Kafka. LinkedIn first created it, and then it was given to the Apache Software Foundation. Kafka offers a scalable, fault-tolerant means to stream data across applications and is built to handle real-time data streams.
Kafka is based on the publish-subscribe model, where producers publish messages to a specific topic, and consumers subscribe to one or more topics to receive those messages. The messages are stored in a distributed cluster, and consumers can pull messages from any partition of the cluster in parallel, enabling high throughput.
Kafka is widely used for building real-time data pipelines, streaming applications, and real-time analytics. It can handle a large volume of data with low latency, making it suitable for use cases such as real-time monitoring, log aggregation, and messaging systems.
What are the core concepts of Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform that is designed to handle real-time data feeds. The core concepts of Kafka are:
Topic: A topic is a category or stream of messages in Kafka. Producers publish messages to a specific topic, and consumers subscribe to one or more topics to receive those messages.
Partition: A partition is a unit of parallelism in Kafka. Each topic is divided into one or more partitions, and each partition is a ordered and immutable sequence of messages. Partitions enable Kafka to scale horizontally across multiple servers.
Consumer Group: A consumer group is a set of consumers that work together to consume messages from a topic. Each consumer group can have multiple consumers, but each message is only consumed by one consumer within a group.
Producer: An application that publishes messages to a Kafka topic is referred to be a producer. Messages can be published by producers either synchronously or asynchronously.
Consumer: A consumer is an application that subscribes to one or more Kafka topics and processes the messages from them. Consumers can read messages from a specific partition or from multiple partitions in parallel.
Offset: An offset is a unique identifier that Kafka assigns to each message within a partition. Consumers use offsets to keep track of the messages they have already consumed.
What is a Kafka Topic?

A Kafka topic is a category or stream of messages in the Kafka messaging system. It is a logical entity that represents a specific stream of data. In Kafka, producers publish messages to a topic, and consumers subscribe to one or more topics to receive those messages.
Topics can be partitioned to enable Kafka to scale horizontally across multiple servers. Each partition is an ordered and immutable sequence of messages, and Kafka stores multiple copies of each partition for fault-tolerance.
Topics are named and can have different configurations, such as the number of partitions, the replication factor, and retention policies. Kafka guarantees that messages published to a topic will be retained for a specified amount of time or until a certain size limit is reached.
Topics can be used to organize data streams, such as logs or events from different sources, and they can be consumed by multiple consumers or consumer groups. By using topics in Kafka, developers can create scalable, fault-tolerant, and flexible data pipelines for real-time data processing and analysis.
What is a Kafka Partition?
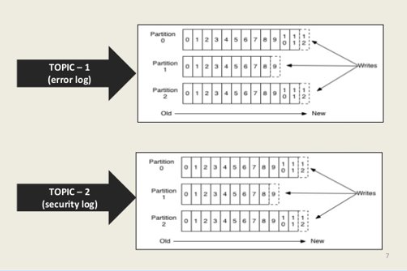
A Kafka partition is a unit of parallelism and scalability in the Kafka messaging system. A partition is a ordered and immutable sequence of messages in a Kafka topic that can be stored on a single broker or multiple brokers in a Kafka cluster. Partitions enable Kafka to handle large volumes of data by allowing messages to be spread across multiple servers in a distributed manner.
Each partition is assigned a unique identifier, called the partition ID, and messages within a partition are ordered by their offset, which is a unique identifier assigned to each message within a partition. Consumers can read messages from a specific partition or multiple partitions in parallel, allowing Kafka to achieve high throughput.
By default, a Kafka topic has only one partition, but it can be divided into multiple partitions for scalability and fault-tolerance. The number of partitions in a topic affects the parallelism of the Kafka cluster, and adding or removing partitions can impact the ordering of messages and the distribution of data across brokers.
Kafka provides configurable options for partitioning, such as the number of partitions per topic and the replication factor for each partition. By using partitions in Kafka, developers can design scalable and fault-tolerant data pipelines that can handle high volumes of data with low latency.
What is a Kafka Consumer Group?
A Kafka consumer group is a set of consumers that work together to consume messages from one or more Kafka topics. Each consumer in a group reads messages from a unique subset of partitions in the topic. Consumer groups enable parallel processing of messages from a topic and provide fault-tolerance by allowing multiple instances of a consumer to share the work of processing messages.
Each consumer group maintains a unique group ID that identifies the group to Kafka. Kafka assigns a subset of partitions in a topic to each consumer in the group based on the group’s ID, allowing multiple consumers to work together without consuming duplicate messages.
When a new consumer joins or leaves a group, Kafka automatically rebalances the partition assignments to ensure that each partition is assigned to only one consumer in the group at any given time. This rebalancing allows Kafka to provide fault-tolerance by ensuring that each partition is always being processed, even if a consumer in the group fails.
Consumer groups are often used in applications that require high throughput and low latency, such as real-time data processing and analytics. By using consumer groups in Kafka, developers can create scalable and fault-tolerant data pipelines that can handle large volumes of data with high concurrency.
How does Kafka ensure fault-tolerance?
Kafka ensures fault-tolerance through replication and partitioning.
Replication is the process of creating multiple copies of each partition across different brokers in the Kafka cluster. This replication ensures that if one broker fails, the data stored on that broker is still available on other brokers, and the Kafka cluster can continue to function without data loss. Each partition can have one or more replicas, and the replication factor determines the number of replicas for each partition. Kafka guarantees that a message published to a topic will be replicated to all replicas before acknowledging the write request to the producer, ensuring that no data is lost in the event of a broker failure.
Partitioning is the process of dividing a topic into multiple partitions. Each partition can be stored on a separate broker, and consumers can read from multiple partitions in parallel. This parallelism provides fault-tolerance by ensuring that if one broker fails, the remaining brokers can continue to process messages from the other partitions in the topic. Kafka also provides automatic partition rebalancing, which ensures that if a broker fails or new brokers are added to the cluster, partitions are automatically reassigned to ensure that each partition is being processed by a single consumer in a consumer group at any given time.
Kafka’s fault-tolerance mechanisms ensure that data is always available even in the face of hardware or software failures. By using replication and partitioning, Kafka can provide a highly available, scalable, and fault-tolerant messaging system for real-time data processing and analysis.
Explain the role of ZooKeeper in Kafka.

ZooKeeper is a centralized service that is used to manage and coordinate distributed systems in Kafka. Kafka uses ZooKeeper to maintain configuration information, handle leader election, and manage distributed synchronization.
The main role of ZooKeeper in Kafka is to store metadata about the Kafka cluster, such as the list of brokers, partitions, and topics. Kafka brokers use ZooKeeper to register themselves and provide their metadata, such as the IP address and the list of topics they host. ZooKeeper also stores information about the partition assignments of each topic and the location of the leader for each partition. This information is critical for Kafka’s fault-tolerance mechanism, as it allows Kafka to recover from failures and ensure that messages are not lost.
Another important role of ZooKeeper in Kafka is to handle leader election. When a broker fails or becomes unavailable, ZooKeeper is responsible for electing a new leader for the affected partitions. This process ensures that messages can still be produced and consumed from Kafka even in the event of broker failures.
ZooKeeper also provides distributed synchronization and locking mechanisms that are used by Kafka to ensure that only one broker can act as a leader for a partition at any given time. This synchronization mechanism ensures that messages are not duplicated or lost during producer or consumer operations.
How can you increase the throughput of Kafka?
There are several ways to increase the throughput of Kafka, including:
Increasing the number of partitions: By increasing the number of partitions in a topic, you can increase the parallelism of the Kafka cluster, allowing more consumers to read and process messages in parallel.
Increasing the number of brokers: Adding more brokers to the Kafka cluster can increase the capacity and throughput of the cluster by distributing the load across more servers.
Optimizing the producer configuration: The producer’s configuration settings such as batch size, linger time, and compression can be adjusted to optimize message throughput.
Optimizing the consumer configuration: The consumer’s configuration settings such as the number of threads, batch size, and fetch size can be adjusted to optimize message processing and increase throughput.
Using compression: Enabling compression for messages can reduce the size of messages and increase the overall throughput of the Kafka cluster.
Using Kafka Connect: Kafka Connect is a framework for building and running connectors that transfer data between Kafka and other systems. Using Kafka Connect can help to offload data processing from the Kafka cluster, improving the overall throughput.
Using partitioning and replication: Partitioning and replication can improve fault-tolerance and increase the throughput of the Kafka cluster by distributing the load across multiple brokers.
By optimizing these factors, you can increase the throughput and scalability of Kafka to handle larger volumes of data and support more concurrent consumers and producers.
Explain the role of Producers in Kafka.
Producers play a crucial role in the Kafka architecture by publishing data to topics in the Kafka cluster. The primary function of a producer is to write messages to Kafka topics, which can then be consumed by one or more consumers.
When a producer sends a message to Kafka, it specifies the topic to which the message should be published. Kafka then appends the message to the end of the log for that topic, creating a new record. The record consists of a key, a value, and metadata that includes the partition to which the record was written and its offset in that partition.
Producers can also configure the level of acknowledgement they require for each message they send. This can be set to either “acks=0” (fire and forget), “acks=1” (the leader will respond with an acknowledgement once it receives the message), or “acks=all” (the leader will not respond with an acknowledgement until all in-sync replicas have received the message).
Producers can also specify custom partitioning strategies to control the placement of messages in different partitions. By default, Kafka uses a hash-based partitioning strategy to distribute messages evenly across all available partitions. However, producers can implement their own partitioning strategy to achieve custom partition placement based on certain criteria, such as message content, message key, or round-robin distribution.
What is a Kafka Connector?
A Kafka Connector is a plug-in that allows data to be imported from or exported to external systems using Kafka. Connectors provide a framework for moving data in and out of Kafka while maintaining fault-tolerance, scalability, and reliability.
Connectors are used to build pipelines that transfer data between Kafka and external systems, such as databases, message queues, file systems, and streaming platforms. They are designed to handle large volumes of data and provide a scalable and fault-tolerant way to move data in and out of Kafka.
Connectors can be either Source Connectors or Sink Connectors. A Source Connector reads data from an external system and publishes it to Kafka, while a Sink Connector reads data from Kafka and writes it to an external system.
Kafka Connect is the core framework for building and running Connectors in Kafka. It provides a REST API for managing and deploying Connectors and a runtime environment for executing Connector tasks.
Some popular Kafka Connectors include the JDBC Connector for importing data from databases, the HDFS Connector for exporting data to Hadoop HDFS, and the Elasticsearch Connector for indexing data into Elasticsearch.
What is Kafka Stream Processing?
Kafka Stream Processing is a distributed computing technology that allows developers to build real-time streaming applications on top of the Kafka messaging system. It enables processing of continuous data streams in real-time, with low latency and high scalability.
Stream Processing in Kafka is achieved through the Kafka Streams API, which provides a high-level abstraction for processing streams of data. The API allows developers to build complex data processing pipelines by defining a set of operations that are executed on each record in a stream.
Kafka Streams supports both stateless and stateful processing, with stateful processing being achieved through the use of interactive queries and state stores. This enables developers to build powerful real-time applications, such as fraud detection, recommendation engines, and real-time analytics.
One of the key benefits of Kafka Stream Processing is its ability to provide fault-tolerant processing, through mechanisms such as state replication and automated failover. This ensures that processing can continue even in the event of node failures or network outages.
Kafka Stream Processing can also be integrated with other technologies in the Kafka ecosystem, such as Kafka Connect and Kafka MirrorMaker, to provide a complete end-to-end streaming solution.
What is the difference between Apache Kafka and Apache Flume?
Apache Kafka and Apache Flume are both distributed data processing systems, but they have different architectures and use cases.
Apache Kafka is a distributed streaming platform designed for real-time data processing and data integration. It is primarily used for building real-time streaming applications and is optimized for high-throughput, low-latency data streaming. Kafka is built on top of a publish-subscribe messaging system and can handle millions of messages per second.
Apache Flume, on the other hand, is a distributed data collection and aggregation system. It is designed for ingesting high-volume, unstructured data from various sources such as log files, social media, and web servers, and storing them in centralized data stores. Flume provides a flexible architecture for routing and processing data flows from multiple sources to multiple destinations, with built-in fault tolerance and scalability features.
In terms of architecture, Kafka uses a distributed publish-subscribe messaging system that consists of topics, partitions, and brokers. Producers write data to topics, and consumers read data from topics. Flume, on the other hand, uses a data flow model that consists of sources, channels, and sinks. Sources collect data from various inputs, channels store the data temporarily, and sinks deliver the data to various destinations.
How does Kafka differ from other messaging systems like RabbitMQ or ActiveMQ?
Kafka differs from other messaging systems like RabbitMQ or ActiveMQ in several ways, including its architecture, use cases, and performance characteristics.
Architecture: Kafka is designed as a distributed system that uses a publish-subscribe model for communication between producers and consumers. Messages are stored in a distributed commit log, and consumers read messages from specific partitions. RabbitMQ and ActiveMQ, on the other hand, use a broker-based architecture, where messages are routed through a central broker.
Use Cases: Kafka is designed for high-throughput, low-latency data streaming and real-time data processing. It is optimized for use cases that involve processing large volumes of data in real-time, such as log aggregation, real-time analytics, and event-driven architectures. RabbitMQ and ActiveMQ are more suited for use cases that involve routing messages between applications or components, such as task queues or publish-subscribe systems.
Performance: Kafka is optimized for high-throughput, low-latency data streaming, and can handle millions of messages per second with minimal overhead. It achieves this by using an efficient storage format and optimized network protocols. RabbitMQ and ActiveMQ, on the other hand, are more flexible but have lower throughput and higher latency.
Scalability: Kafka is highly scalable and can handle large volumes of data across multiple nodes, with built-in support for partitioning, replication, and failover. RabbitMQ and ActiveMQ can also scale horizontally, but require more configuration and management overhead.
What is the role of Kafka Connect?
Kafka Connect is a framework for building and running data import/export connectors for Apache Kafka. Its primary role is to simplify and automate the process of integrating data between Kafka and external systems or data sources.
Kafka Connect provides a standard set of APIs, protocols, and tools for building and deploying data connectors, which makes it easier to develop, test, and deploy connectors across different environments. It supports both source connectors (which import data into Kafka from external systems) and sink connectors (which export data from Kafka to external systems), and provides built-in support for common data formats and protocols.
By using Kafka Connect, organizations can more easily integrate data from different sources into Kafka, such as databases, message queues, and web services. They can also more easily export data from Kafka to external systems, such as data lakes, analytics tools, and data warehouses. This helps to streamline the process of building real-time data pipelines and enables organizations to more easily build and maintain data-driven applications.
What is the importance of Kafka Schema Registry?
Schema Evolution: As data evolves over time, it is essential to ensure that the changes made to the schema are backward-compatible with existing data consumers. Kafka Schema Registry helps to manage schema evolution by providing a central repository for storing and managing schemas, which ensures that all data producers and consumers use compatible schema versions.
Data Consistency: When data is serialized in Kafka, it is essential to ensure that the data is consistent across different systems that consume the data. Kafka Schema Registry ensures data consistency by enforcing schema validation rules, which helps to prevent incompatible data from being produced or consumed.
Flexibility: Kafka Schema Registry supports multiple serialization formats, such as Avro, JSON, and Protobuf. This makes it flexible and compatible with a wide range of data sources and data consumers.
Compatibility: Kafka Schema Registry is designed to work seamlessly with other Kafka components, such as Kafka Connect and Kafka Streams, which makes it easy to build end-to-end data pipelines that can handle large volumes of data in real-time.
References : Apache Kafka
Other Blogs : Our Blogs



